Reliability, Availability, Maintainability, and Safety (RAMS)
ESB is proven to run in the field continuously for years with 100% up-time.
The 4 components of ESB implement High Availability and Disaster Recovery processes. Each one as a separate entity.
ESB LOGIC and RabbitMQ utilize Microsoft Failover Cluster.
Elastic Search has its own Cluster High Availability.
Classic Apache ActiveMQ has its own cluster High Availability.
Regarding High Availability timings:
ESB Logic works in Active-Hot Standby mode. Failover time is less than 1 second. During this time clients sending information to ESB Logic will fail and retry (TCP retries failed packets). Once the standby is responding – the retries will succeed and all traffic flow continues as normal with no loss.
RabbitMQ works in Active-Hot Standby mode. Once the active fails, it fails traffic is diverted immediately to the Hot Standby with 0 packet loss.
Elastic Search cluster is configured in Remote Cluster Synchronization mode. Thus, all logs are replicated in real time to the second cluster (in SDC). Once the Active node fails – traffic is immediately diverted to the second node with 0 log loss.
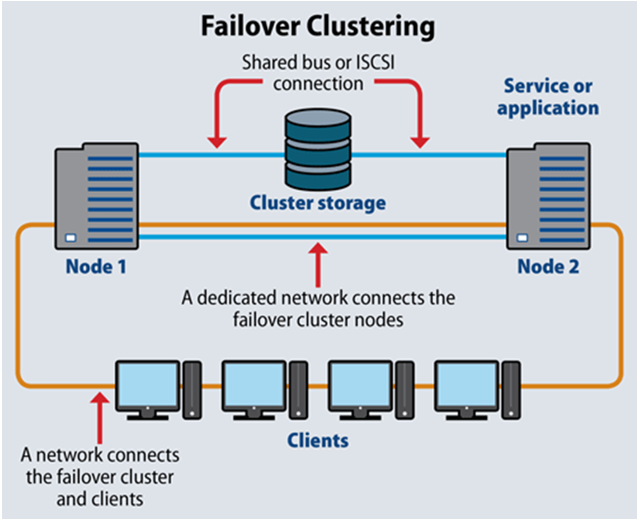
ESB Failover Clustering
ESB Logic
The solution uses two cluster members, one in the MDC (Main Data Center) and one in the SDC (Secondary Data Center). ESB Logic is a Windows-based application that runs on the Windows Server operating system. It leverages the Microsoft failover cluster mechanism to detect and identify any malfunctions of the operating system and/or the application itself by querying the application services.
ESB Logic High Availability is of the Active/Hot Standby type. By default, the Active node is running in the MDC and the Hot Standby node is in the SDC. Switching between Active and Hot Standby (and vice versa) is managed by the Microsoft failover cluster, using a Virtual IP mechanism. The Virtual IP is assigned to one of the two cluster members at any given time. Clients always access the Virtual IP and are unaware of whether it is assigned to the MDC or SDC member.
The Microsoft failover cluster uses a quorum (voting) mechanism to decide which node should be Active. In a setup with two cluster members, best practice is to add a “witness” cluster member. This member only participates in the voting process to determine the Active node and does not have application capabilities.
Synchronization strategy: The configuration file, which contains only setup data/configuration, will be synchronized manually between the cluster nodes as part of ongoing maintenance, not in response to a failure.
RabbitMQ
Similarly to the ESB Logic, RabbitMQ uses two cluster members, one in the MDC (Main Data Center) and one in the SDC (Secondary Data Center). It is a Windows-based application that runs on the Windows Server operating system. It leverages the Microsoft failover cluster mechanism to detect and identify any malfunctions of the operating system and/or the application itself by querying the application services.
RabbitMQ High Availability is of the Active/Hot Standby type. By default, the Active node is running in the MDC and the Hot Standby node is in the SDC. Switching between Active and Hot Standby (and vice versa) is managed by the Microsoft failover cluster, using a Virtual IP mechanism. The Virtual IP is assigned to one of the two cluster members at any given time. Clients always access the Virtual IP and are unaware of whether it is assigned to the MDC or SDC member.
The Microsoft failover cluster uses a quorum (voting) mechanism to decide which node should be Active. In a setup with two cluster members, best practice is to add a “witness” cluster member. This member only participates in the voting process to determine the Active node and does not have application capabilities.
Synchronization strategy: No synchronization is required. Topics are set up automatically on demand on each node.
Elastic Search
The solution uses 2 ELK cluster nodes (servers) with full roles and 1 cluster member (server) with voting only role. The two full nodes are one in the MDC and one in the SDC. The node with voting only role will be in a neutral location, i.e. not in MDC and not in SDC.
Voting means selecting the master node. For proper operation of an ELK cluster there must always be one active master.
The three-node strategy will survive loss of any one of the 3 nodes and will continue regular operation with an elected master.
All the indices (tables of ELK DB) will be replicated between the MDC and SDC.
Further details regarding ELK cluster redundancy can be found at the following link: https://www.elastic.co/guide/en/elasticsearch/reference/current/scalability.html
Further details regarding 3 node redundancy can be found at the following link (section “Two-node clusters with a tiebreaker”): https://www.elastic.co/guide/en/elasticsearch/reference/current/high-availability-cluster-small-clusters.html
The number of primary shares for each index is planned to be 10. Each will have one replica shard. ELK behind the cover, replicates information in the shards.
The ESB Logic component is the only real time component accessing the ELK cluster - in order to log messages and other logging information.
ESB Logic keeps an ongoing health check on both ELK cluster members in MDC and SDC. It prefers the MDC ELK. If, however, MDC ELK is down it will log to SDC ELK. When MDC ELK is back up, it will return to it.
Apache ActiveMQ
The solution uses two ActiveMQ cluster nodes (servers) configured as a “Network of Brokers” to provide a high availability (HA) solution. More details can be found here: https://activemq.apache.org/networks-of-brokers
Clients will use the failover:// transport protocol. They will primarily connect to the master broker in the MDC (Main Data Center). If the master broker fails, the clients will automatically switch to the slave broker in the SDC (Secondary Data Center).